
This is part of a series of articles in which I’m trying to teach myself about BI. Any related articles I write are preceded with “#BI101” in the title.
Because this is a new (to me) topic, it’s possible that what I write might be inaccurate. I invite you to correct me in the comments, and I will make it a point to edit this article for accuracy.
As part of my personal education about business intelligence, I kicked off a SkillSoft course made available to me through my employer. My strategy is to take the course, perform some supportive research, and write about what I learn. It turned out that BI was one of the training options available. So, I kicked off the course and began my training.
The initial topic discussed the concept of data warehousing. The course began with a pre-test — a proverbial “how much do I really know?” There were a few subtopics that were familiar to me — normalization and denormalization, for one — so my initial thought was, how much do I have to learn? As it turned out, the answer was, a lot.
What is a data warehouse, and what does it do?
The short and simple answer is that a data warehouse is, as the name implies, a storage repository for data.
That’s the short answer. The longer answer gets a little more complicated.

I learned that a lot of the concepts behind a data warehouse pretty much breaks a lot of what I thought I knew about relational databases. For starters, I’ve always been under the impression that all relational databases needed to be normalized. However, I learned that, in the case of a data warehouse, that might not necessarily be the case. While a data warehouse could be normalized, it might not necessarily be. While a normalized database is designed to minimize data redundancy, a denormalized data table might have redundant data. Although it occupies more space, having redundant data reduces the number of table joins, thus reducing query time (as the SkillSoft lesson put it, sacrificing storage space for speed). When a data warehouse is storing millions of rows of data, reducing the number of query joins could be significant.
Populating a data warehouse
How does data get into a data warehouse? It turns out that a data warehouse can have multiple data sources — SQL Server, Oracle, Access, Excel, flat files, and so on. The trick is, how does this data get into a data warehouse? This is where the integration layer comes in.
Because the SkillSoft course I took was SQL Server-specific, it focused on SSIS. SSIS provides tools that allow it to connect to multiple data sources, as well as tools for ETL (Extract, Transform, Load). ETL involves a process that includes obtaining data from the various sources and processing it for data warehouse storage. A big part of ETL is data cleansing — formatting data so it is usable and consistent. For example, imagine that several data sources use different formats for the same Boolean data field. One uses “1” and “0”, another uses “T” and “F”, another uses “Yes” and “No”, and so on. Data cleansing formats these fields into a single, consistent format so that it is usable by the data warehouse. As there are many such fields, ETL is often a very long and involved process.
Just the facts, ma’am…
I had heard of fact and dimension tables before, but I wasn’t entirely sure about their application until I started diving into BI. In a nutshell, facts are raw data, while dimensions provide context to the facts.
To illustrate facts and dimensions, let me go back to one of my favorite subjects: baseball. How about Derek Jeter’s hitting statistics? Clicking “Game Log” displays a list of game-by-game statistics for a given season (the link provided defaults to the 2014 season, Jeter’s last season). Looking at his last home game on Sept. 25, Jeter accumulated two hits, including a double, driving in three runs, scoring once, and striking out once in five at-bats. These single-game numbers are the facts. The facts are these raw numbers that Jeter generated in that single game. A fact table stores these individual game statistics in a single table. Dimensions provide context to these numbers. Some dimensions might include total accumulated statistics for a season, batting average, and some (non-statistical) information about Jeter himself (name, hometown, birth date, etc.). These derived statistics would be stored in dimension tables.
If you’re still confused about fact and dimension tables, I found this question on StackOverflow that does a pretty good job of answering the question. I also came across this article that also does a good job of describing fact and dimension tables.
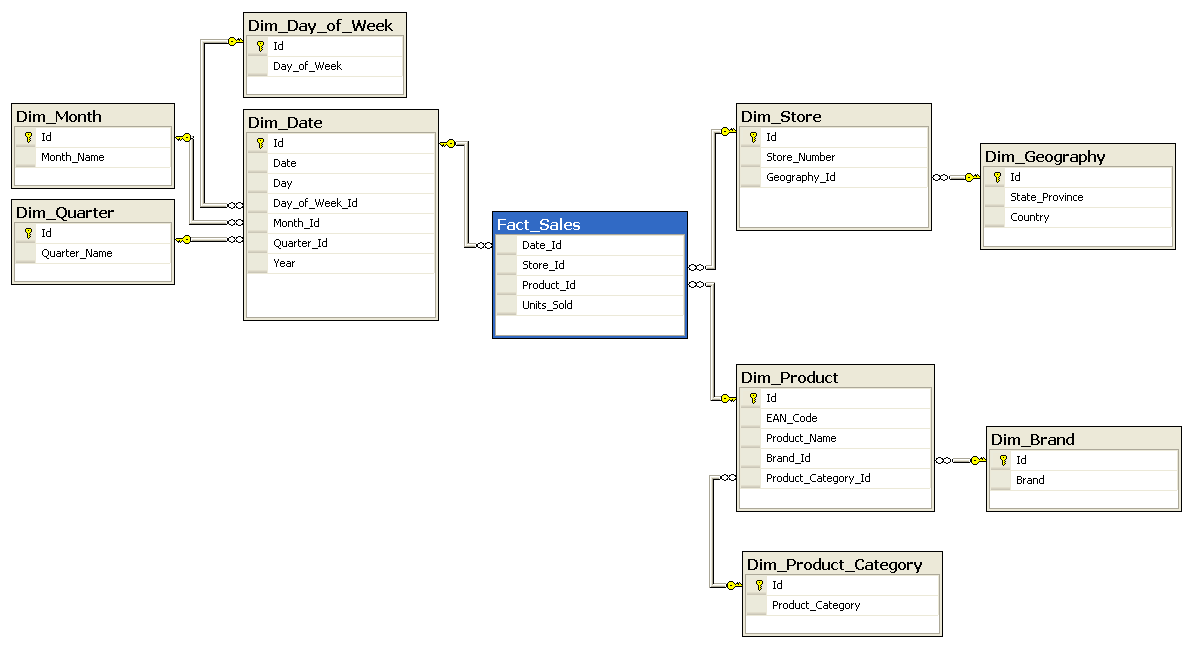
Stars and snowflakes

A fact table usually maintains a relationship with a number of dimension tables. The fact table connects to the dimension tables through a foreign key relationship. The visual table design usually resembles a star, in which the fact table is at the center and the dimension tables branch out from the center. For this reason, this structure is called a star schema.
A snowflake schema is related to the star schema. The main difference is that the dimension tables are further normalized. The resulting foreign key relationships result in a schema that visually resembles a snowflake.
Attention, data-mart shoppers…
A data mart can probably be considered either a smaller version of a data warehouse, or a subset of a data warehouse (a “dependent” data mart, according to Wikipedia). As I understand it, a data warehouse stores data for an entire corporation, organization, or enterprise, whereas a data mart stores data for a specific business unit, division, or department. Each business unit utilizes data marts for various information purposes, such as reporting, forecasting, and data mining. (I’ll likely talk about these functions in a separate article; for our purposes, they go outside the scope of this article.)
So, this winds up what I’ve learned about data warehousing (so far). Hopefully, you’ll have learned as much reading this article as I have writing it. And hopefully, you’ll keep reading along as I continue my own education into BI. Enjoy the ride.
