

It's official! We will be hosting a SQL Saturday here in Albany, NY on August 3! Click the link for more information, to register for the event, or to submit a presentation! SQL Saturday Albany is an all-day technical training event organized by the Capital Area SQL Server User Group. This event provides data-centric training … Continue reading We’re hosting a #SQLSaturday! August 3 — save the date! #SQLSat1083 #SQLSatAlbany
Category: Data security
September CASSUG Monthly Meeting #Networking @CASSUG_Albany

Our September meeting will again be online. NOTE: you MUST RSVP to this Meetup at https://www.meetup.com/Capital-Area-SQL-Server-User-Group/events/280614945/ to view the Zoom URL! Our September speaker is Kathi Kellenberger! Topic: What is DevOps and Why Should DBAs Care? Our online meeting schedule is as follows: 6:00: General chat, discussion, and announcements6:30: Presentation We usually wrap up between … Continue reading September CASSUG Monthly Meeting #Networking @CASSUG_Albany
The Value of Paper vs Convenience of Digital
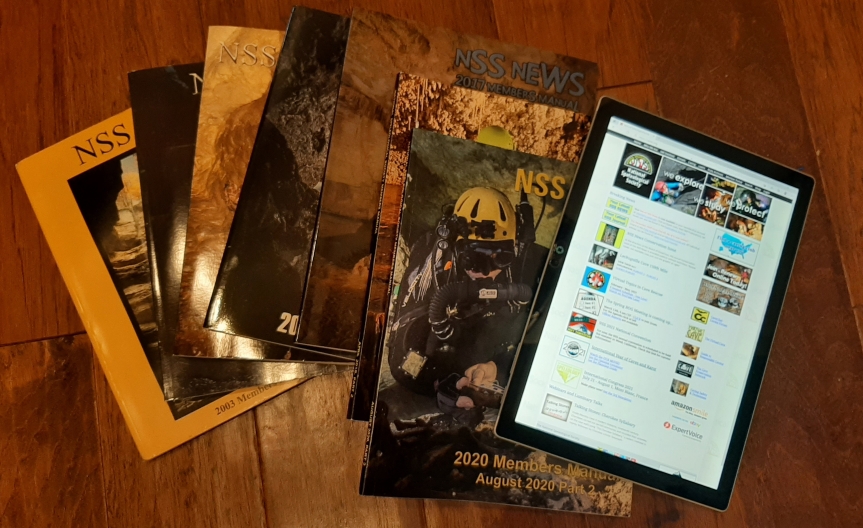
I wrote a while back that, while digital documentation dominates the world today, paper isn’t necessarily dead. That said, my friend, Greg Moore, notes an issue with printed material that didn’t occur to me, and it has to do with data security. Read on for more.
About 35 years ago in the fall, a housemate of mine got a phone call, “hey, I’m a caver who’s passing through your area this weekend and found your name in the NSS Members’ Manual, I was hoping maybe you could hook me up with a caving trip.” Well it just so turns out that the RPI Outing Club traditionally does Friday night caving. (Why night you might ask? Well it’s always dark in the caves, so going at night leaves time on Saturday and Sunday to hike, rock-climbing, canoe, etc.) My housemate invited the guy along and he joined us caving (I think in Knox Cave).
I mention this story because it’s an example of how the NSS Members’ Manual has often been used over the years. Talk to enough old-time caves (especially those who recognize the smell of carbide in the morning) and many will mention how they’ve…
View original post 1,404 more words
#SQL101: Raising awareness of SQL injection
(Image credit: XKCD.com) I don't think there's an experienced web developer or DBA who isn't familiar with the classic "Bobby Tables" XKCD cartoon above. Just about any time you mention "Bobby Tables" to most experienced IT people, (s)he will immediately know to whom you are referring. Most experienced web developers and DBAs are aware of … Continue reading #SQL101: Raising awareness of SQL injection
Think spam calls aren’t a big deal? Think again
We all get them. There's a message on your voicemail saying "we've been trying to reach you about your warranty" or "we've detected problems with your computer." They're full of crap, and you know it. You figure that they're mere annoyances. You don't answer the phone anymore, or you've installed a spam filter on your … Continue reading Think spam calls aren’t a big deal? Think again
#SQLSaturday #961 Albany — TOMORROW! July 25 #SQLSat961 #SQLSatAlbany
IMPORTANT! If you are attending SQL Saturday, you MUST register on the SQL Saturday website (NOT Meetup or Facebook) at https://www.sqlsaturday.com/961! This is a reminder that tomorrow, July 25, CASSUG will host Albany SQL Saturday for the seventh time! And for the first time, Albany SQL Saturday is going virtual! We will have a full day of great … Continue reading #SQLSaturday #961 Albany — TOMORROW! July 25 #SQLSat961 #SQLSatAlbany
January CASSUG Monthly Meeting
Greetings, data enthusiasts! Our next CASSUG monthly meeting is on Monday, January 13! Our January speaker is Grant Fritchey! He will present his topic titled “10 Steps Towards Global Data Compliance.” For additional information and to RSVP, go to our Meetup event page at https://www.meetup.com/Capital-Area-SQL-Server-User-Group/events/267111279/ Additionally, I will present a lightning talk about my experience … Continue reading January CASSUG Monthly Meeting
When it’s appropriate to use fake data (no, really!!!)
It isn't uncommon for me to include data examples whenever I'm writing documentation. I've written before about how good examples will enhance documentation. Let me make one thing clear. I am not talking about using data or statistics in and of itself to back up any assertions that I make. Rather, I am talking about … Continue reading When it’s appropriate to use fake data (no, really!!!)
#SQLSaturday #892 Providence — the debrief #SQLSat892 #SQLFamily
I arrived home last night around 9:15, after driving four hours (including an hour-long dinner break) from Providence, RI. As usual, it was another great SQL Saturday! As always, I had a blast! And as always, I was wiped out after it was over! Even as I write this, on this Sunday afternoon, I had … Continue reading #SQLSaturday #892 Providence — the debrief #SQLSat892 #SQLFamily
Ransomware and DevOps
Another post by Steve Jones that I think is really important…
Ransomware.
A scary topic and one attack that is apparently more common than I suspected. Before you go further, if you haven’t restored a database backup in the last month, stop and go verify your DR plan works. That’s one of the overconfident issues facing lots of government and businesses. While this might not help your entire organization, at least you’ll have some confidence in your process and that you can recover a database.
This is a great article from Ars Technica and worth reading: A take of two cities: Why ransomware will just get worse. I’d recommend you read it and think about a few things. First, do you have insurance because things (or substitute your own word here) happen? Second, have you really tested a DR plan for some sort of software issue like this? You might think about a way to restore systems in an air-gapped…
View original post 356 more words
